Implementation details
Note
This section provides additional design insights on how we implemented the Parfun library. Most users should not be required to go through this section in detail.
Design goals
Distribute the computation of parallelized functions on multiple servers.
Users of the decorator should not be required to know anything about the underlying infrastructure.
The system should automatically determine the optimal partition size.
Implementation
Parfun uses on either a local or a distributed worker pool to manage and execute tasks on multiple
machines (see the BackendEngine interface).
This parallel engine is responsible for queuing and executing the partitioned tasks. The library relies on heuristics to determine the ideal partition size based on feedback from the previously executed tasks.
Partition size estimation
Parfun determines the best partition size for parallelization by testing the function on a range of partition sizes. This is called the learning phase.
There are multiple ways of determining the optimal partition size, depending on what constraints you wish to optimize. We designed our partition size estimator so that it finds a partition size that provides decent parallelism without overusing too much computing resources. In other words, our estimator will prefer a 10x speedup that requires 15 cores to a 12x speedup that requires 50 cores.
Consider the following graph of how our relative_metrics() function performs on various partition sizes:
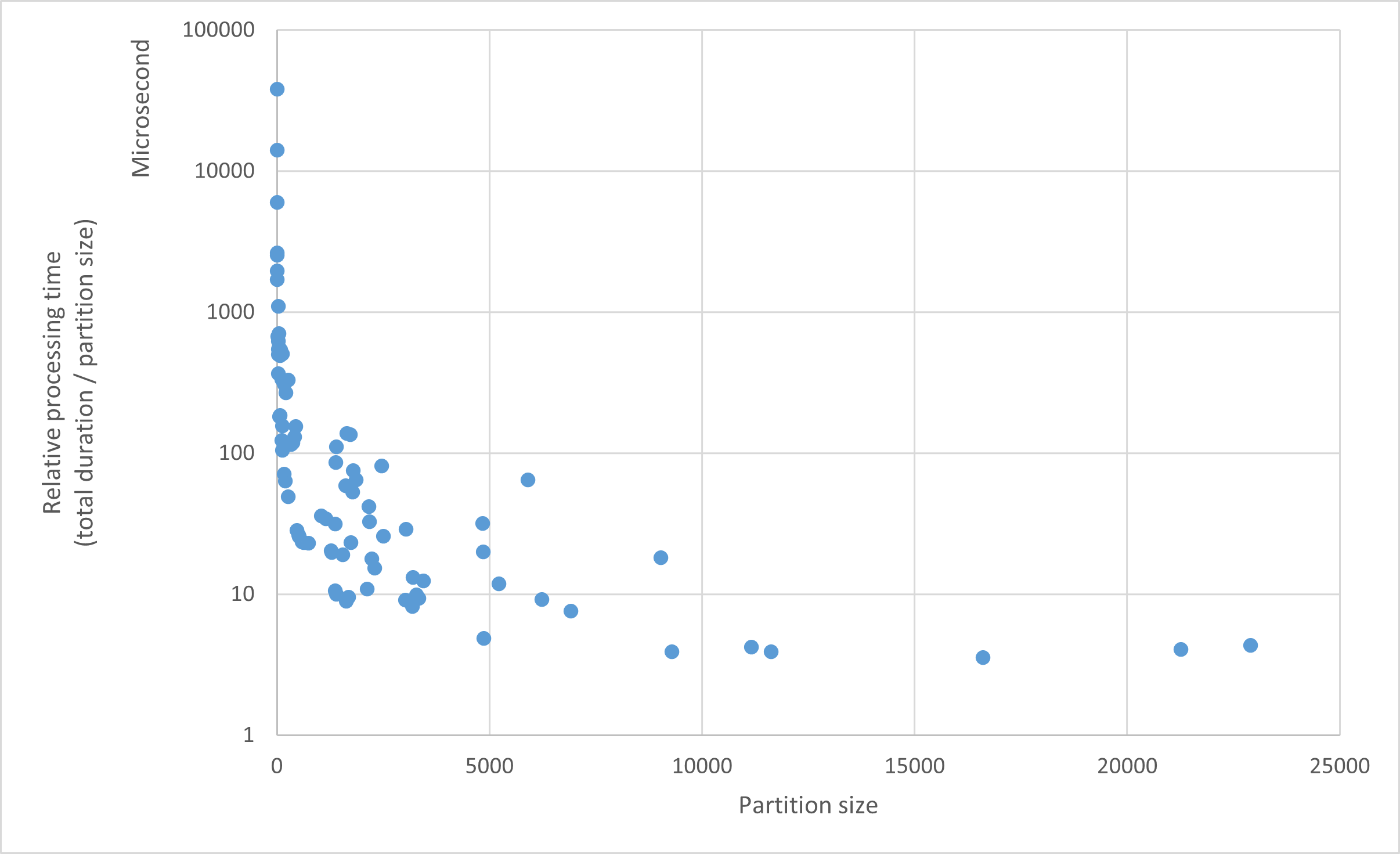
We observe that the relative processing speed (i.e., the time to process one dataset row) drops dramatically as partition size increases, but stabilizes around a partition size of about 3000 (graph is log scale). This tells us that smaller partition sizes cause too much overhead (code initialization, input preprocessing …), while partition sizes above a few thousands do not significantly reduce the overhead.
Mathematically, we could fit a linear function f(partition_size) = α + β / partition_size, where α would be the
time it takes to process one row, and β the function scheduling and initialization duration:
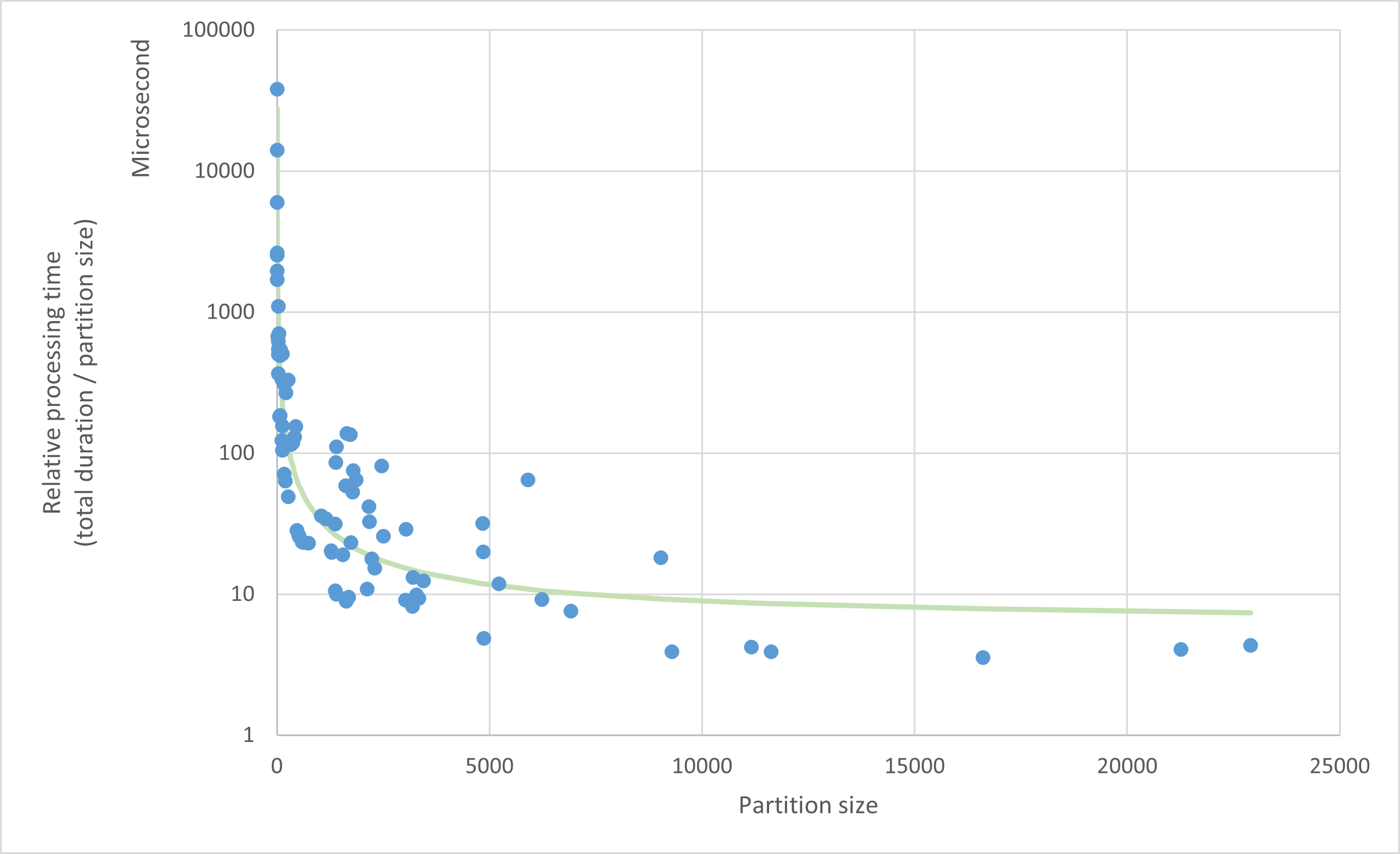
Knowing α and β, the partition size estimator finds a partition size that satisfies these two constraints:
The function initialization time (
β) should be less than 5% of the total execution time. This ensures that parallelization overhead is balanced with the actual processing time.The processing of a single partition should at least exceed the CPU time required to schedule the task. There is some unmeasured overhead (IPC, OS task management) that will make parallelization of short tasks inefficient.
Based on these constraints, the estimator suggests a partition size of about 2000 for our example function (relative_metrics()).