Quickstart
When to use it
Scaler is inspired by Dask and functions like other parallel backends. It handles the communication between the Client, Scheduler, and Workers to orchestrate the execution of tasks. It is a good fit for scaling compute-heavy jobs across multiple machines, or even on a local machine using process-level parallelization.
Architecture
Below is a diagram of the relationship between the Client, Scheduler, and Workers.
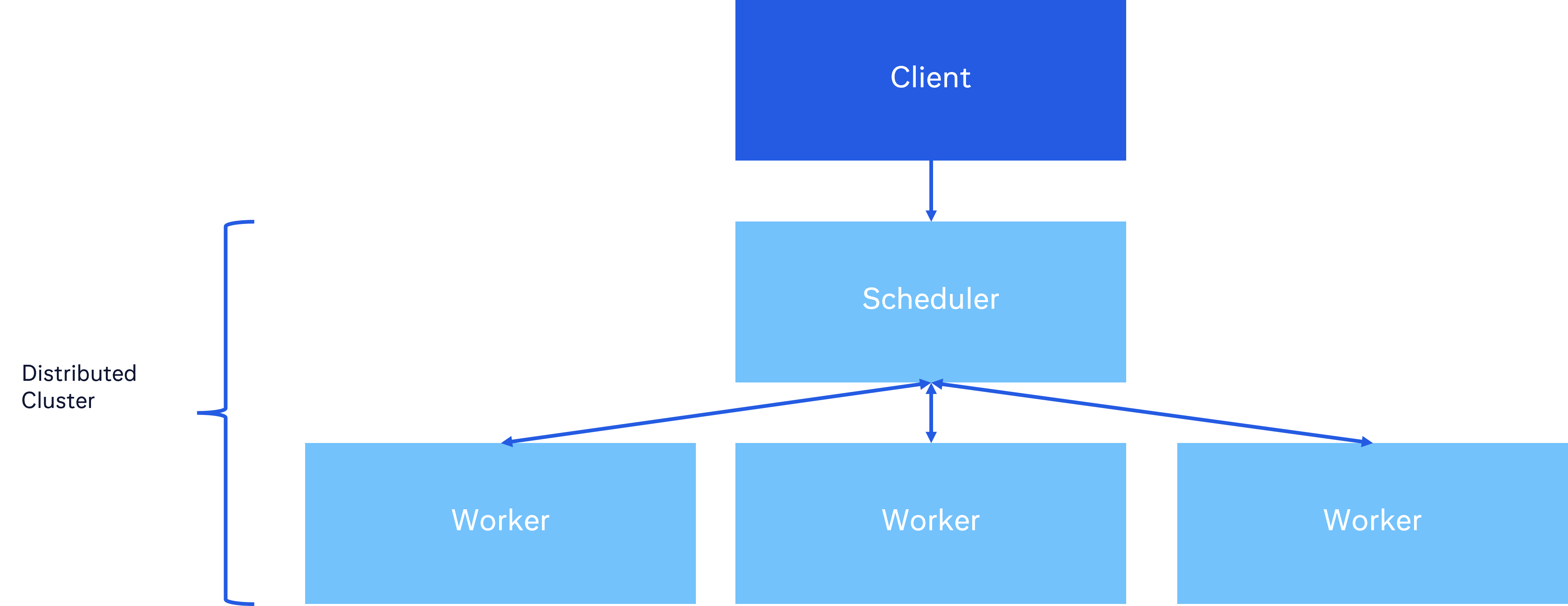
The Client submits tasks to the scheduler. This is the primary user-facing API.
The Client is responsible for serializing the tasks
The Scheduler receives tasks from the client and distributes the tasks among the workers
Workers perform the computation and return the results
Note
Although the architecture is similar to Dask, Scaler has a better decoupling of these systems and separation of concerns. For example, the Client only knows about the Scheduler and doesn’t directly see the number of workers.
Installation
The scaler package is available on PyPI and can be installed using any compatible package manager.
pip install scaler
First Look (Code API)
Client.map
map() allows us to submit a batch of tasks to execute in parallel by pairing a function with a list of inputs.
In the example below, we spin up a scheduler and some workers on the local machine using SchedulerClusterCombo. We create the scheduler with a localhost address, and then pass that address to the client so that it can connect. We then use map() to submit tasks.
"""
This example shows how to use the Client.map() method.
Client.map() allows the user to invoke a callable many times with different values.
For more information on the map operation, refer to
https://en.wikipedia.org/wiki/Map_(higher-order_function)
"""
import math
from scaler import Client
from scaler.cluster.combo import SchedulerClusterCombo
def main():
# For an explanation on how SchedulerClusterCombo and Client work, please see simple_client.py
cluster = SchedulerClusterCombo(n_workers=10)
with Client(address=cluster.get_address()) as client:
# map each integer in [0, 100) through math.sqrt()
# the first parameter is the function to call, and the second is a list of argument tuples
# (x,) denotes a tuple of length one
results = client.map(math.sqrt, [(x,) for x in range(100)])
# Collect the results and sums them
result = sum(results)
print(result)
cluster.shutdown()
if __name__ == "__main__":
main()
Client.submit
There is another way of to submit task to the scheduler: submit(), which is used to submit a single function and arguments. The results will be lazily retrieved on the first call to result().
"""
This example demonstrates the most basic implementation to work with scaler
Scaler applications have three parts - scheduler, cluster, and client.
Scheduler is used to schedule works send from client to cluster.
Cluster, composed of 1 or more worker(s), are used to execute works.
Client is used to send tasks to scheduler.
This example shows a client sends 100 tasks, where each task represents the
execution of math.sqrt function and get back the results.
"""
import math
from scaler import Client
from scaler.cluster.combo import SchedulerClusterCombo
def main():
# Instantiate a SchedulerClusterCombo which contains a scheduler and a cluster that contains n_workers workers. In
# this case, there are 10 workers. There are more options to control the behavior of SchedulerClusterCombo, you can
# check them out in other examples.
cluster = SchedulerClusterCombo(n_workers=10)
# Instantiate a Client that represents a client aforementioned. One may submit task using client.
# Since client is sending task(s) to the scheduler, we need to know the address that the scheduler has. In this
# case, we can get the address using cluster.get_address()
with Client(address=cluster.get_address()) as client:
# Submits 100 tasks
futures = [
# In each iteration of the loop, we submit one task to the scheduler. Each task represents the execution of
# a function defined by you.
# Note: Users are responsible to correctly provide the argument(s) of a function that the user wish to call.
# Fail to do so results in exception.
# This is to demonstrate client.submit(). A better way to implement this particular case is to use
# client.map(). See `map_client.py` for more detail.
client.submit(math.sqrt, i)
for i in range(0, 100)
]
# Each call to Client.submit returns a future. Users are expected to keep the future until the task has been
# finished, or cancelled. The future returned by Client.submit is the only way to get results from corresponding
# tasks. In this case, future.result() will return a float, but this can be any type should the user wish.
result = sum(future.result() for future in futures)
print(result) # 661.46
cluster.shutdown()
if __name__ == "__main__":
main()
Things to Avoid
please note that the submit() method is used to submit a single task. If you wish to submit multiple tasks using the same function but with many sets of arguments, use map() instead to avoid unnecessary serialization overhead. The following is an example what not to do.
import functools
import random
from scaler import Client, SchedulerClusterCombo
def lookup(heavy_map: bytes, index: int):
return index * 1
def main():
address = "tcp://127.0.0.1:2345"
cluster = SchedulerClusterCombo(address=address, n_workers=3)
# a heavy function that is expensive to serialize
big_func = functools.partial(lookup, b"1" * 5_000_000_000)
arguments = [random.randint(0, 100) for _ in range(100)]
with Client(address=address) as client:
# we incur serialization overhead for every call to client.submit -- use client.map instead
futures = [client.submit(big_func, i) for i in arguments]
print([fut.result() for fut in futures])
cluster.shutdown()
if __name__ == "__main__":
main()
This will be extremely slow, because it will serialize the argument function big_func() each time submit() is called.
Functions may also be ‘heavy’ if they accept large objects as arguments. In this case, consider using send_object() to send the object to the scheduler, and then later use submit() to submit the function.
Spinning up Scheduler and Cluster Separately
The scheduler and workers can be spun up independently through the CLI. Here we use localhost addresses for demonstration, however the scheduler and workers can be started on different machines.
scaler_scheduler tcp://127.0.0.1:8516
[INFO]2023-03-19 12:16:10-0400: logging to ('/dev/stdout',)
[INFO]2023-03-19 12:16:10-0400: use event loop: 2
[INFO]2023-03-19 12:16:10-0400: Scheduler: monitor address is ipc:///tmp/0.0.0.0_8516_monitor
[INFO]2023-03-19 12:16:10-0400: AsyncBinder: started
[INFO]2023-03-19 12:16:10-0400: VanillaTaskManager: started
[INFO]2023-03-19 12:16:10-0400: VanillaObjectManager: started
[INFO]2023-03-19 12:16:10-0400: VanillaWorkerManager: started
[INFO]2023-03-19 12:16:10-0400: StatusReporter: started
scaler_worker -n 10 tcp://127.0.0.1:8516
[INFO]2023-03-19 12:19:19-0400: logging to ('/dev/stdout',)
[INFO]2023-03-19 12:19:19-0400: ClusterProcess: starting 10 workers, heartbeat_interval_seconds=2, object_retention_seconds=3600
[INFO]2023-03-19 12:19:19-0400: Worker[0] started
[INFO]2023-03-19 12:19:19-0400: Worker[1] started
[INFO]2023-03-19 12:19:19-0400: Worker[2] started
[INFO]2023-03-19 12:19:19-0400: Worker[3] started
[INFO]2023-03-19 12:19:19-0400: Worker[4] started
[INFO]2023-03-19 12:19:19-0400: Worker[5] started
[INFO]2023-03-19 12:19:19-0400: Worker[6] started
[INFO]2023-03-19 12:19:19-0400: Worker[7] started
[INFO]2023-03-19 12:19:19-0400: Worker[8] started
[INFO]2023-03-19 12:19:19-0400: Worker[9] started
From here, connect the Python Client and begin submitting tasks:
from scaler import Client
address = "tcp://127.0.0.1:8516"
with Client(address=address) as client:
results = client.map(calculate, [(i,) for i in tasks]
assert results == tasks